基因演算法 NSGAII
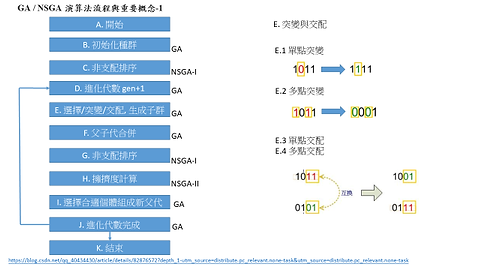
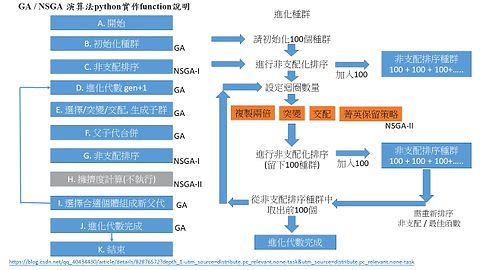
目前我們主要練習題目都使用NSGAII,因為我們在練習多目標的最佳化。首先我們先隨機產生一些基因(100組),根據我們所設定的目標函數計算出這些基因裡面最好基因,由最好至最爛開始排序,排好之後把他丟到一個非支配排序表(control table)裡面做一個非支配排序,然後從control table裡面取出最好的幾組基因(我們通常取前100組),先把這100組基因複製一遍變200組,先把最好的前3組基因保留(菁英保留策略),再從這200組基因選第3~100組做突變(隨機挑一個位置的基因把她隨機變成別的基因),101組~200組做交配(隨機挑選2組基因的幾個位置,讓他們跟另一組的基因做交換),好了之後就完成了第一次迭代,再把第二代這200組基因做排序,排好了之後取前100組放進control table,再把control table進行非支配排序,接著就一直重複這幾個動作,當她一直迭代排序之後找到一組與我們所設定的目標值最接近的基因時,這組基因就是我們要的最佳化的基因。
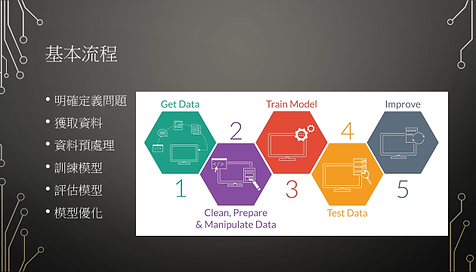
機器學習
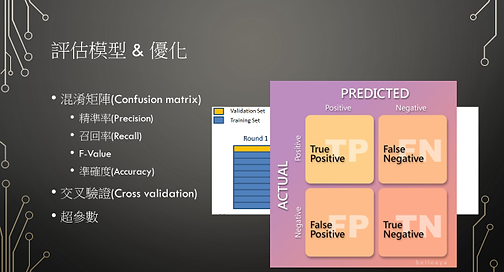
大概有分為監督式、非監督式、強化式學習,我們這學期主要是練習監督式學習。監督式學習又可分為分類問題與迴歸問題(Classification、Regression)。要讓機器學習東西需要先給它大量資料,但是資料都要先經過處理,要先檢查有沒有缺失值、重複值,然後作特徵工程,從原有的資料中,人工的創造出一些新資料,可以第A比 + 第B比之類的,特徵工程做完之後做特徵轉換,數值資料如果有些差異過大可以先取log再做,如果不是數字的資料稱為類別資料,要先把他們轉成數字,因為電腦只會讀取數字,都做完後把這些特徵做縮放,也就是資料標準化、正規化,最後就是選擇自己想要套用的訓練模型,然後印出模型的評估和優化。
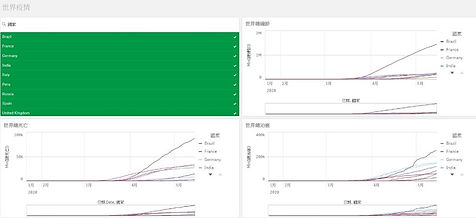
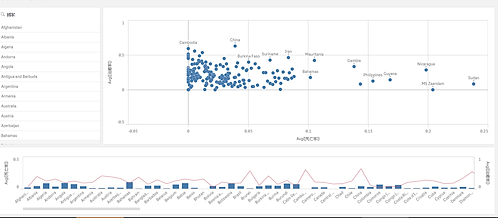
Qlik視覺化軟體
我們把全球開放的疫情資料抓取下來,放入Qlik視覺化軟體去做分析,把資料變成圖表。其中可以選取各個國家,來做確診、死亡、治癒的比較。